Ortelius Blog
Topics include Supply Chain Security, Microservice Management, Neat Tricks, and Contributor insights.
How Ortelius Models Threats with ML Workflows - A Roadmap
Why are Threat Models Needed? What’s the Problem?
Developers around the globe are consuming open-source packages all day long. One “npm install” and BOOM the new intern can now single-handedly code your carefully architected payment flow service. Developers can do more with less training, and software can be delivered in record speed. Open-source has made software development faster and easier.
The the flip side of this has some cause for concern. As OS packages and dependencies start increasing in the corporate codebase, the offices of the CISO and CTO have no easy way to keep track of the potential cybersecurity risk of every OS component consumed, not to mention the robustness of each package.

Image source: XKCD
Data is Fragemented in Current Application Security Tools
There are many new application secuity tools on the market that are important to address this broad problem of open-source security. The Linux Foundation’s OpenSSF has gathered together the ‘giants’ including Google, IBM and Intel, to address come up with answers. The commercial application security market is growing at a record pace. Everyone is talking about SBOMs.
Two primary problems exists with the addition of these new tools.
-
First, automation of security tooling is essential. That level of automation is needed in DevOps pipelines. These pipelines are static and need manual updates. There are millions of these workflow scripts that need enhancement of basic security tooling. Just ponder for a minute what it would take to add Software Bill of Material generaiton to 100 million Jenkins workflows. The Ortelius team is pondering this question and looking at ways to address the issue. They are currently looking at the use of CDEvents to automate the addition of new tools into the pipeline.
-
Second, organizations are moving to decoupled archtictures. Most security tooling is based on a single GitHub Repo that supports the creation of a single service, with it’s own independent workflow. That service is updated all day long impacting every ’logical’ application that consumes it. While cloud-native is a critical new architecutre, it is also a very complex one. The new data created by many new application security tools is fragmented across thousands of artifacts that have deep dependencies. This complexity is too much for a human to track in spreadsheets alone.
The Ortelius open-source project is working to solve these two basic problems. Ortelius is incubating at the Continuous Delivery Foundation.
What Does Ortelius Do?
The Ortelius platform aggregates security and DevOps data for every component, building a vast amount of security data that is mapped to deployment data. For example, Ortelius can show where a particular open-source package is used across all deployed environments. This consolidated DevSecOps data can be used to build machine learning (ML) workflows for accessing and generating threat models, a feature on the Ortelius roadmap.
Particularly useful is the platform’s architecture and how it tracks updates and dependencies, like building a family tree with versions and relationships. This approach enhances security intelligence by identifying, visualizing and addressing potential risks in software development and deployment. All provided in real time.
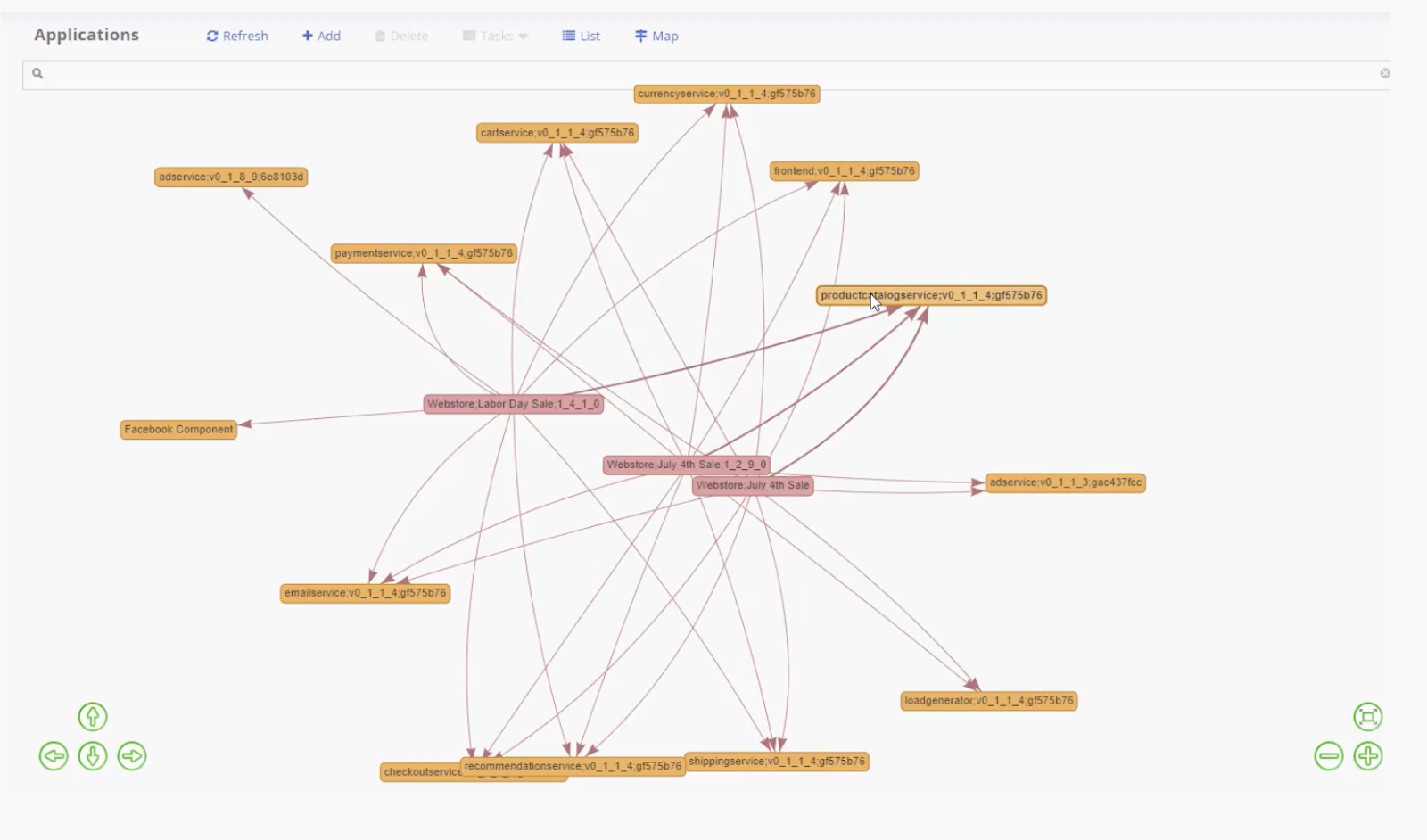
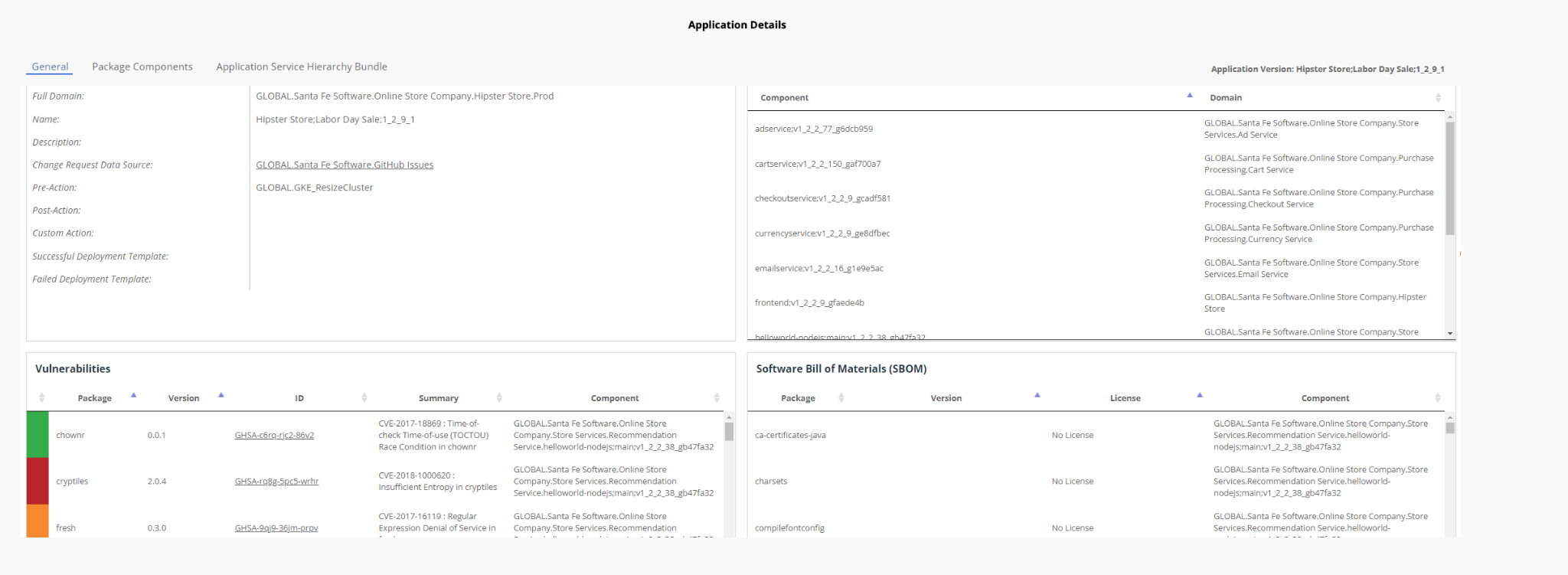
Ortelius also provides a top-down view of all the dependencies and flags all the vulnerabilities according to severity. Additionally, this level of insights could allow Ortelius to deploy known defenses (aka “mitigations”) when a vulnerability is flagged as high-risk.
What Threat Model Logic is the Ortelius Community Working Toward?
The Ortelius Community is beginning to analyze how the Ortelius data could be used to build ML workflows based on particular threats. For example, if our bright intern is using a package that is now vulnerable to “Content Injection”, then Ortelius in real time could:
- Looks up and logs the known ‘tactic’ (TA0040 is its ID in MITRE list).
- Find the ‘mitigation’ for the vulnerability in the MITRE ATT&CK list (ID: M1021 in MITRE List).
- Deploys the known mitigation (M1021) and restricts web based content in the developer environment.
- This reduced criticality is flagged on the CISO’s dashboard and a new ticket is opened with the DevSecOps’ team to further work on it
Note: MITRE is a free database for threat models that has a battle tested mitigations list for enterprise, mobile and other tactics like content injection, man-in-the middle attacks.
Yes, But What’s the Catch?
There are always points of failures. For example, in our above scenario, what if Ortelius can’t find a mitigation for the tactic that the hacker is using. This is where mapping, similarity scores and Machine Learning comes into play.
Using “Similarity Scores” in the Ortelius workflow, Ortelius could go find a new package, from a repository with a lower risk score, and create a pull request to replace the package that has a zero-day vulnerability. This is where Machine Learning can really play a big part.
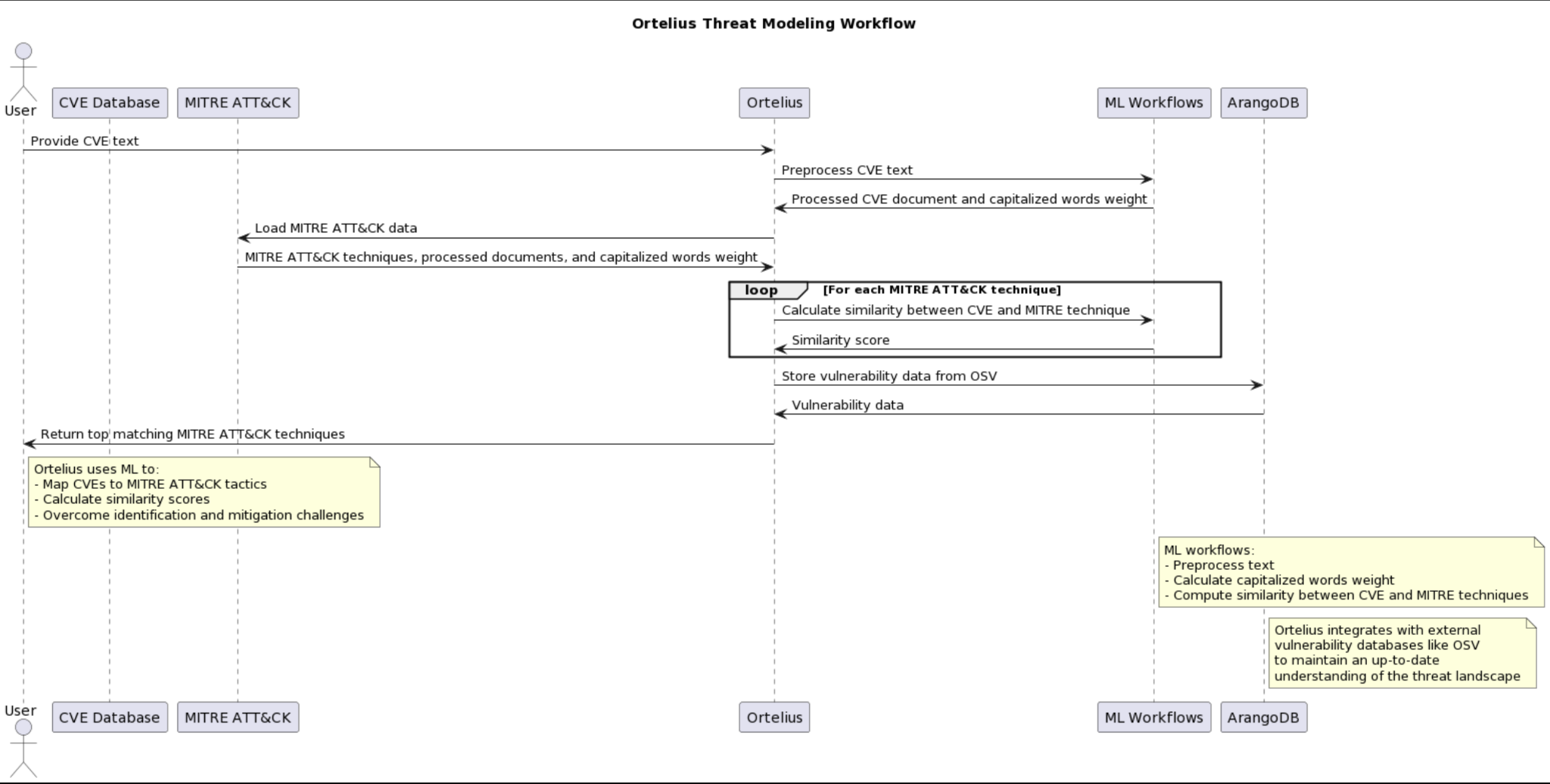
Workflow Explanation
-
Ortelius pulls data daily from osv.dev to maintain an up-to-date understanding of the threat landscape. This vulnerability data is added to Ortelius’ ArangoDB database for further processing.
-
Standardizing, Processing and Vectorization:
-
Preprocessing of Text: The text of vulnerabilities is preprocessed to standardize terminology and remove irrelevant information. This ensures that the ML model can focus on the most relevant aspects of the vulnerability descriptions.
-
Natural Language Processing (NLP): Ortelius uses the Stanza NLP library to tokenize, lemmatise, and filter out stop words from the vulnerability descriptions. This NLP processing results in a cleaner, more focused set of terms that represent the essence of each vulnerability.
-
TF-IDF Vectorization: The processed text is then transformed into TF-IDF vectors, which capture the importance of terms within the vulnerability descriptions relative to their frequency across all descriptions. This representation allows for more effective comparison of textual data.
-
Cosine Similarity: Ortelius calculates the cosine similarity between the TF-IDF vectors of vulnerability descriptions and those of MITRE ATT&CK techniques. This similarity score quantifies the closeness of a given vulnerability to known attack techniques, facilitating the mapping process.
-
Mapping and Scoring: Based on the similarity scores, Ortelius maps vulnerabilities to the most relevant MITRE ATT&CK techniques. The system prioritizes mappings with higher similarity scores, ensuring that the most likely associations are identified.
Conclusion
The data that Ortelius gathers as part of it’s evidence store provides deep insights into how a single vulnerability impacts security across the entire organizaiton. This data can be used to automatically remediate against high-risk vulnerabilites as soon as they are found.
Our example of an Ortelius ML workflow enables Ortelius to dynamically map vulnerabilities to the MITRE ATT&CK framework with a high degree of accuracy, even as new vulnerabilities and attack techniques are discovered. By automating this mapping process, Ortelius has the potential to significantly enhance the ability of security teams to understand and mitigate potential threats in their software environments.
The model is dependent on the real time data pulled from osv.dev and MITRE ATT&CK and thus solves for tactics and mitigations identified by them daily.
References and Citations:
- MITRE Attack
- Common Vulnerabilities and Exposures Maintained
- Common Vulnerabilities
- Ortelius catalog of DevSecOps Data
